统计计算
配套教材为 统计计算 田霞,徐瑞民,孙倩
个人思路,仅供参考
习题1.1
第1题
根据幂函数的误差传递规则,体积的相对误差为半径相对误差的 3 倍:
已知体积的相对误差限为 1%,代入公式得:
测量半径 R 时允许的相对误差限为 0.00333
第3题
根据公式
得 m = -1 ,m - n + 1 = -5 得 n = 5 ,即有效数字有5位。
第5题
绝对误差限
$x$ 的相对误差限为 $\varepsilon$,即满足:其中 是 $x$ 的近似值, $\Delta x = x^* - x$。
对于函数 $f(x) = \ln x$,其一阶泰勒展开近似为:
绝对误差为:
代入 $|\Delta x| \leq \varepsilon x$ 得:
绝对误差限为 $\varepsilon$
相对误差限
相对误差限定义为绝对误差限与函数值的绝对值之比:代入绝对误差限 $\varepsilon$,相对误差限即 $|\frac{\varepsilon}{\ln x^*}|$
第7题
$x$ 的可能范围为: $0.17525 \leq x < 0.17535$
最大绝对误差为 $|x - x^*| < 0.5 \times 10^{-4}$
即绝对误差限为 $0.5 \times 10^{-4}$
第9题
求递推公式
写出
分拆被积函数
因此
计算积分并代回
从而得到递推关系
即
1 | import sympy as sp |
习题1.2
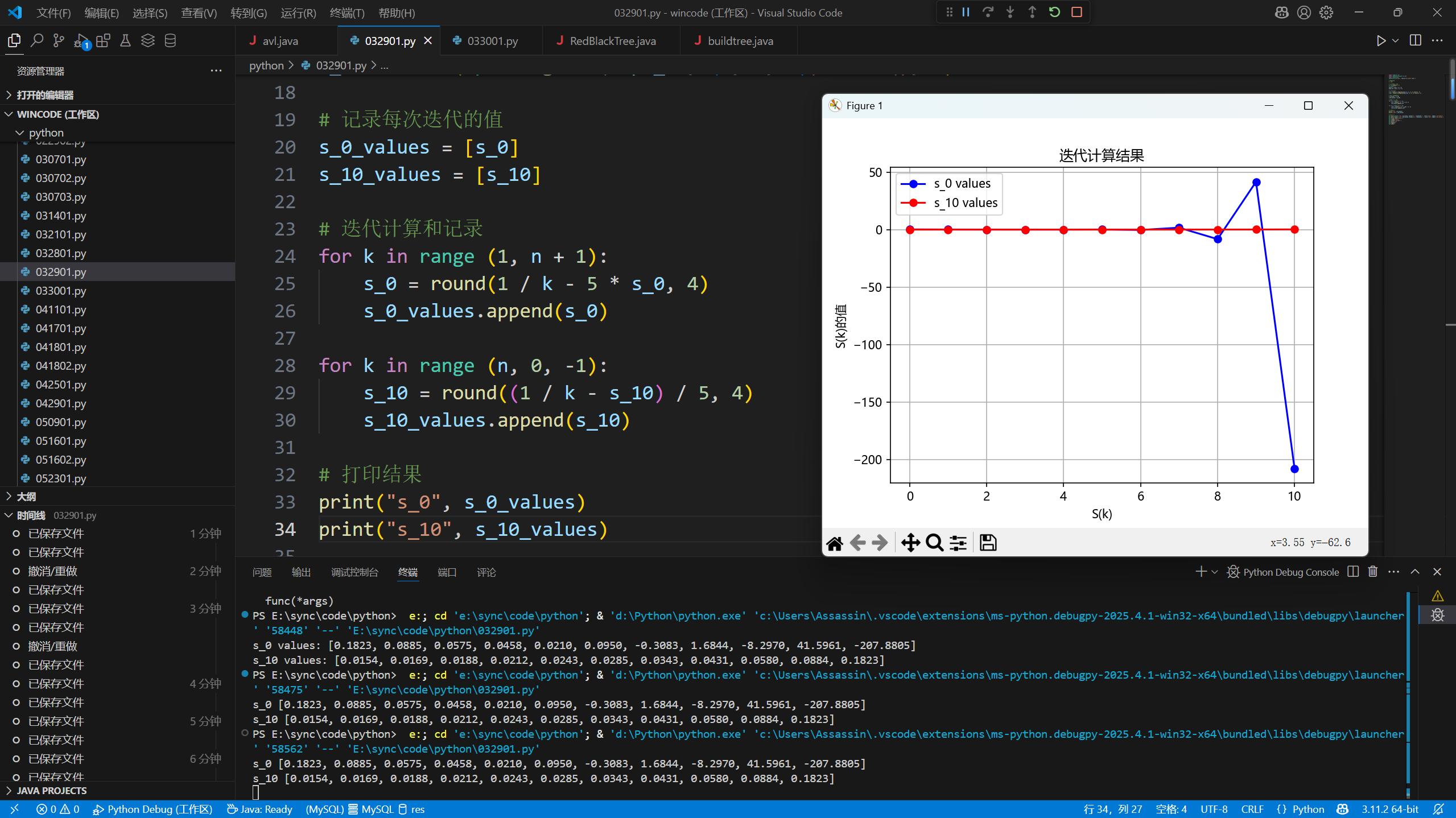
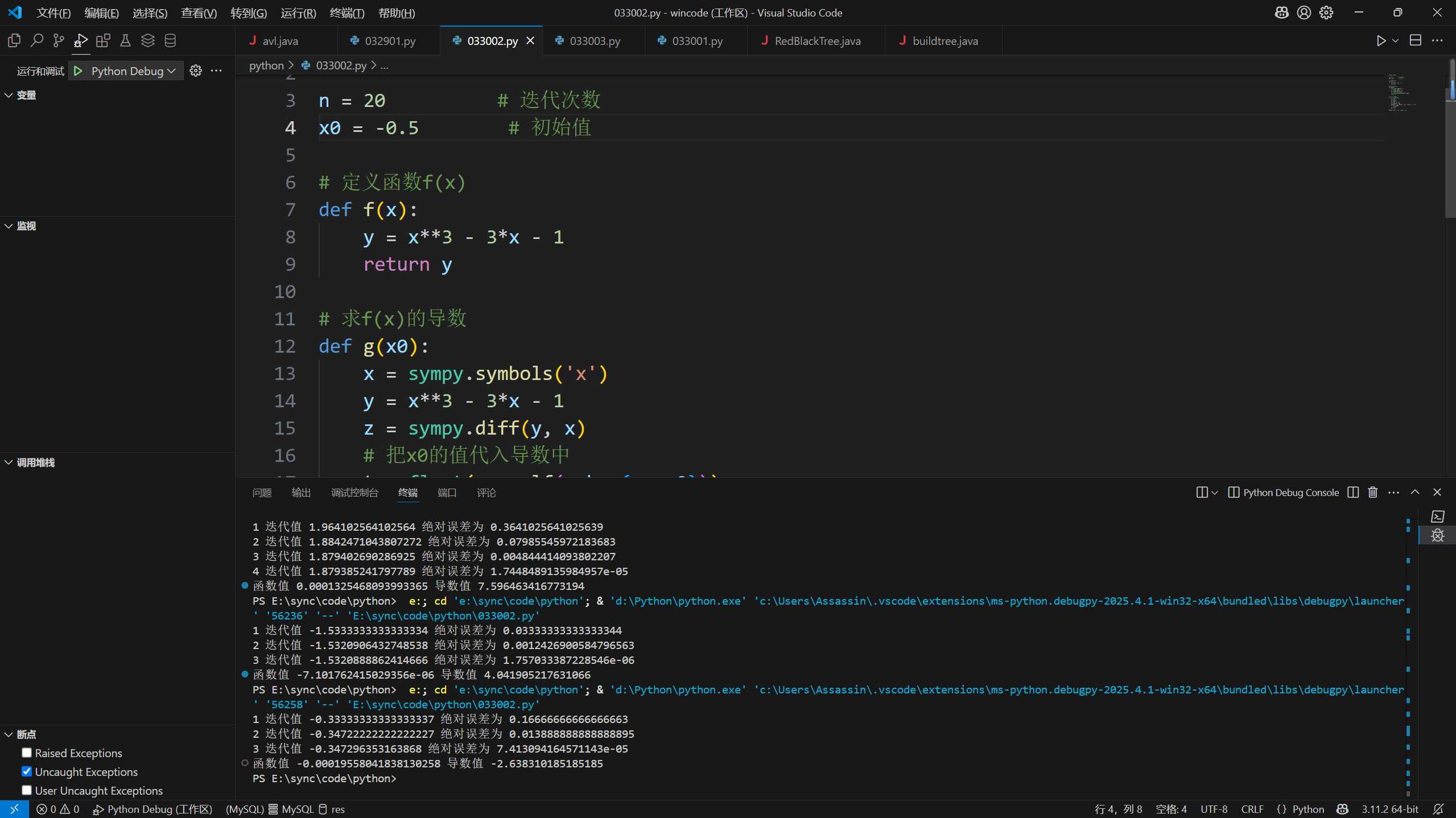
第2题
三个解
迭代值 1.879385241571822 绝对误差为 8.309744825574228e-08
迭代值 -0.347296353163868 绝对误差为 7.413094164571143e-05
迭代值 -1.5320888862414666 绝对误差为 1.757033387228546e-061
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import sympy
n = 20 # 迭代次数
x0 = 1.5 # 初始值(-1.5, -0.5)
# 定义函数f(x)
def f(x):
y = x**3 - 3 * x - 1
return y
# 求f(x)的导数
def g(x0):
x = sympy.symbols('x')
y = x**3 - 3 * x - 1
z = sympy.diff(y, x)
# 把x0的值代入导数中
t = float(z.evalf(subs={x: x0}))
return t
# 用牛顿法求根
for i in range(n):
k = x0
s = f(k)
t = g(k)
x1 = k - s / t
e = abs(x1 - x0)
print(i + 1, '迭代值', x1, '绝对误差为', e)
if e < 0.0001:
break
x0 = x1
print('函数值', s, '导数值', t)
第4题
最优解为: -2 取得最优解时自变量为 [-2, 2, 2]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# 下山法
# 给出x1,x2,x3取值范围
xr = [[-2, 5], [2, 6], [-5, 2]]
bs = [3, 5, 2] # 初始值
def f(x1, x2, x3):
y = x1 + x2 - x3
return y
# bev:bestevaluete, bv:bestvalue
while True:
bev = f(bs[0], bs[1], bs[2])
bv = bev
so = [bs]
t = len(bs)
for i in range(t):
if bs[i] > xr[i][0]:
so.append(bs[0:i] + [bs[i]-1] + bs[i+1:])
if bs[i] < xr[i][1]:
so.append(bs[0:i] + [bs[i]+1] + bs[i+1:])
for s in so:
el = f(s[0], s[1], s[2])
# 取所有el中最小的
if el < bev:
bs = s
bev = el
print(bs, bev)
if bev == bv:
break
print('最优解为:', bv, '取得最优解时自变量为', bs)
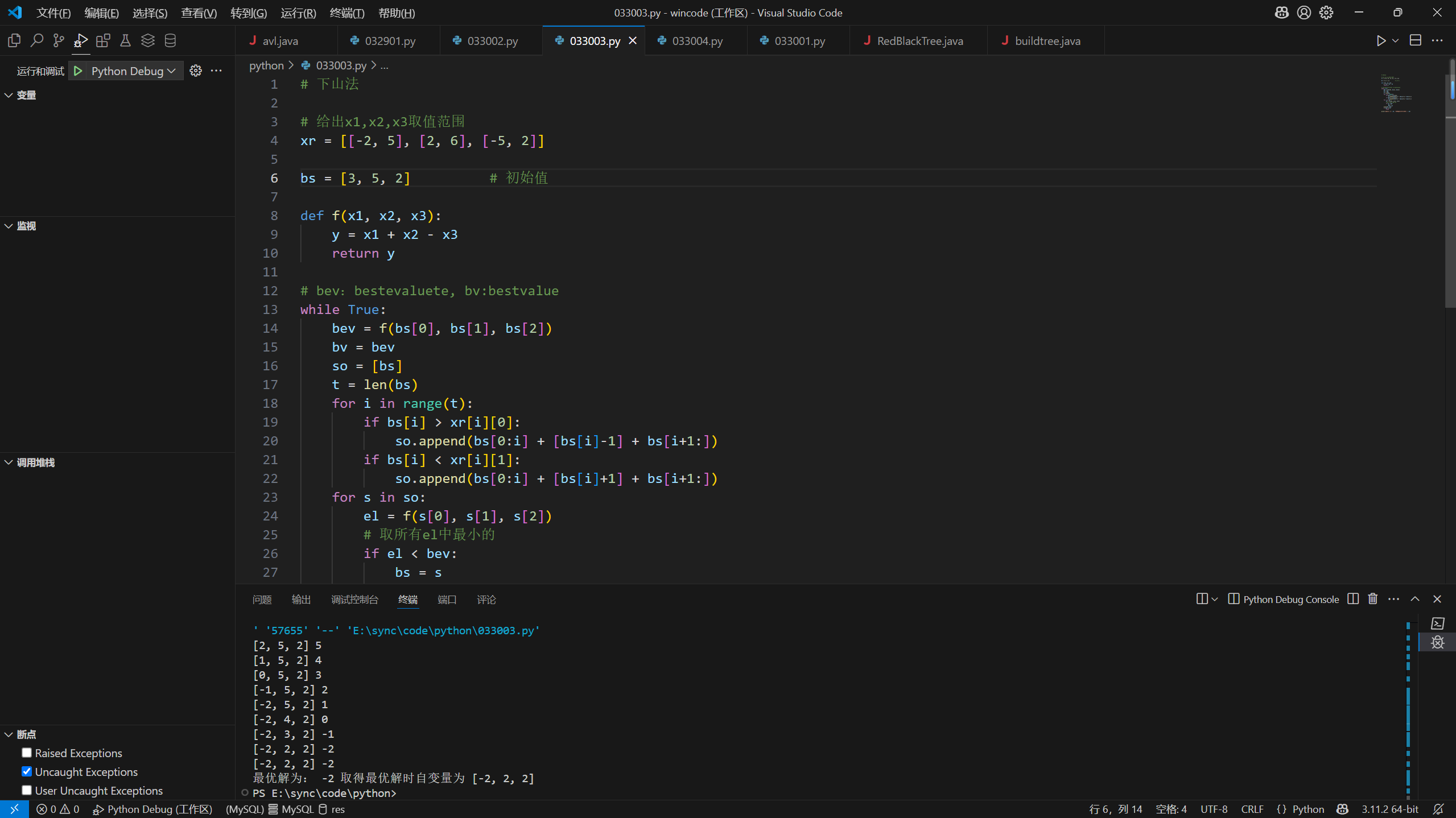
第6题
最优解为: -2 取得最优解时自变量为 [-2, 2, 2]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# 下山法
import random
# 给出x1,x2,x3取值范围
xr = [[-2, 5], [2, 6], [-5, 2]]
# 随机选择初始值,确保在范围内
bs = [random.randint(r[0], r[1]) for r in xr]
def f(x1, x2, x3):
y = x1 + x2 - x3
return y
# bev:bestevaluete, bv:bestvalue
while True:
bev = f(bs[0], bs[1], bs[2])
bv = bev
so = [bs]
t = len(bs)
for i in range(t):
if bs[i] > xr[i][0]:
so.append(bs[0:i] + [bs[i]-1] + bs[i+1:])
if bs[i] < xr[i][1]:
so.append(bs[0:i] + [bs[i]+1] + bs[i+1:])
for s in so:
el = f(s[0], s[1], s[2])
# 取所有el中最小的
if el < bev:
bs = s
bev = el
print(bs, bev)
if bev == bv:
break
print('最优解为:', bv, '取得最优解时自变量为', bs)
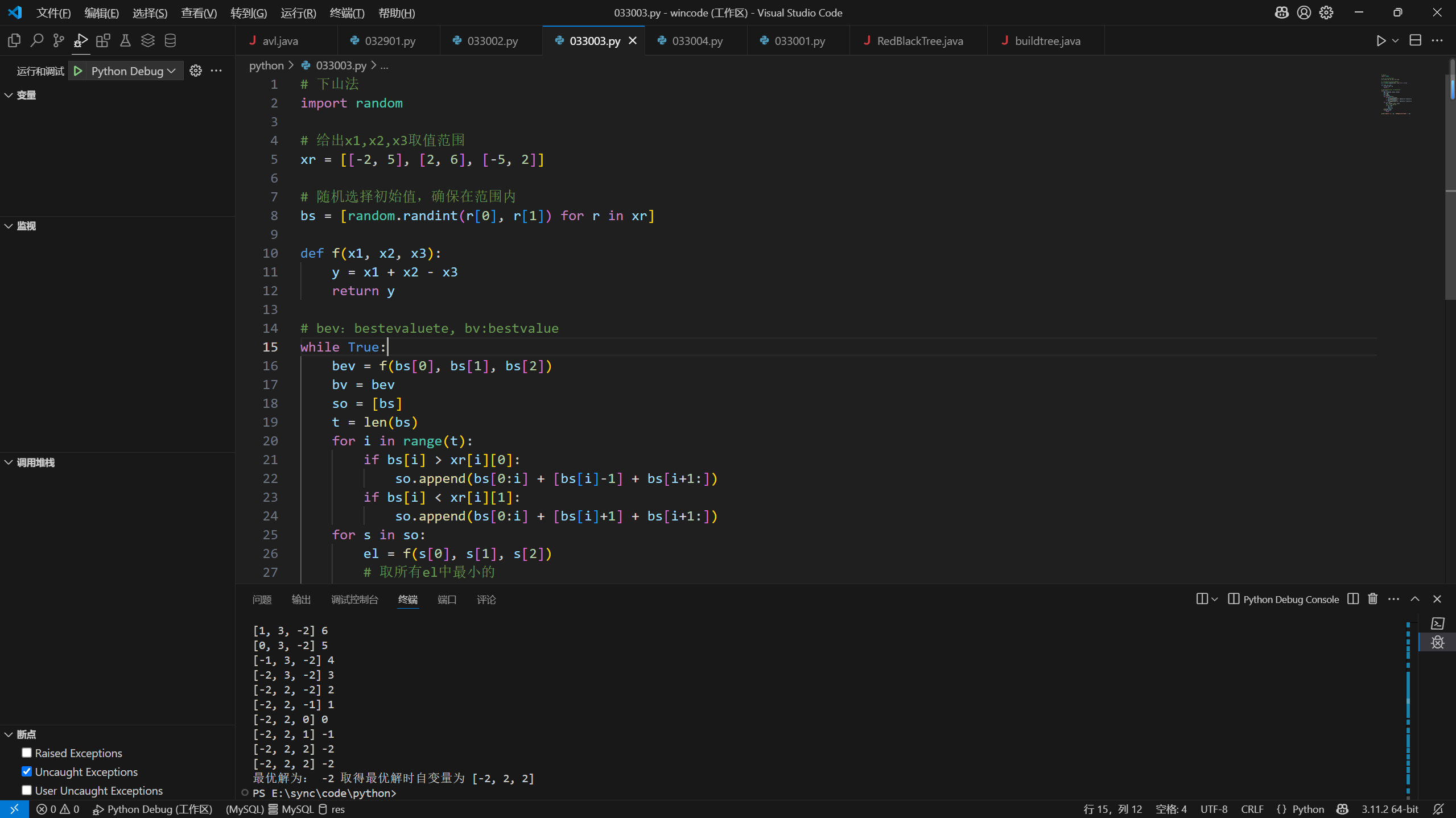
第8题
最优点: (0.0000, 0.0000)
函数最小值: 0.00001
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import math
# 目标函数
def f(x, y):
return x**2 + y**2
# 梯度函数
def grad(x, y):
return (2 * x , 2 * y)
x, y = 1.0, 3.0 # 初始点
step = 0.4 # 步长
max_iters = 50 # 最大迭代次数
tolerance = 1e-6 # 精度
for i in range(max_iters):
g_x, g_y = grad(x, y)
# 打印当前x, y值
print("迭代{}: x = {:.6f}, y = {:.6f}, 函数值 = {:.6f}".format(i, x, y, f(x, y)))
# 判断收敛条件:梯度模长足够小
if math.sqrt(g_x**2 + g_y**2) < tolerance:
break
# 梯度下降更新
x -= step * g_x
y -= step * g_y
print("最优点: ({:.4f}, {:.4f})".format(x, y))
print("函数最小值: {:.4f}".format(f(x, y)))
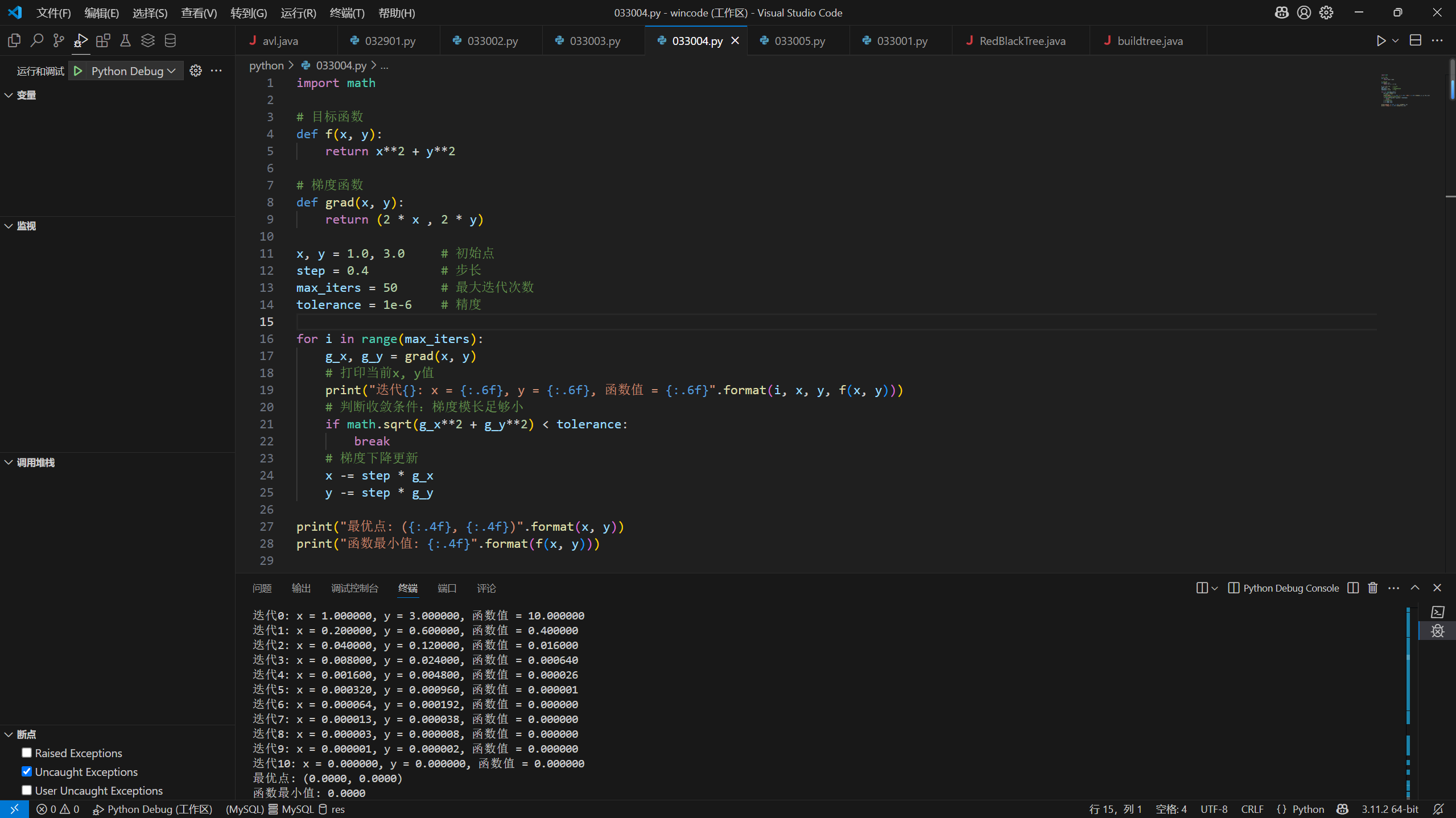
第10题
近似根: (0.999530, 0.000000)
函数值: 0.0000001
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import math
# 目标函数
def f(x, y):
return 2 * (x - 1)**2 + y**2
# 梯度函数
def grad(x, y):
return (4 * (x - 1), 2 * y)
x, y = 2.0, 2.0 # 初始点
step = 0.4 # 步长
max_iters = 50 # 最大迭代次数
tolerance = 1e-6 # 精度
for i in range(max_iters):
g_x, g_y = grad(x, y)
# 打印当前x, y值
print("迭代{}: x = {:.6f}, y = {:.6f}, 函数值 = {:.6f}".format(i, x, y, f(x, y)))
# 判断收敛条件:函数值接近0
if f(x, y) < tolerance:
break
# 梯度下降更新
x -= step * g_x
y -= step * g_y
print("近似根: ({:.6f}, {:.6f})".format(x, y))
print("函数值: {:.6f}".format(f(x, y)))
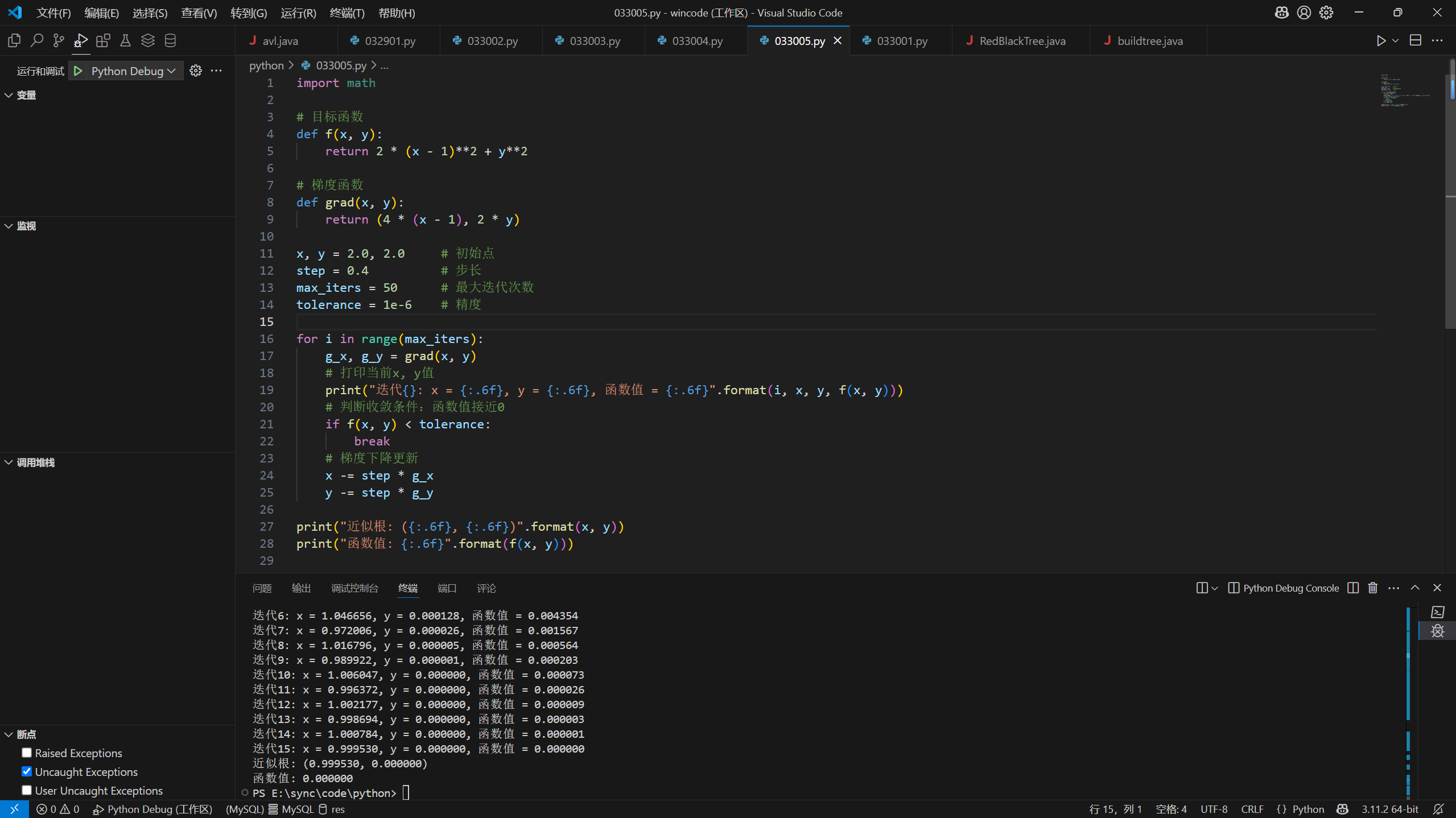
习题2.1
第2题
4个随机数为:[2563, 5689, 3647, 3006, 360]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28#创建一个列表来存储随机数
x = []
x0 = 2563
#将种子作为第一个随机数
x.append(x0)
#需要n个随机数
n = 4
for i in range (n):
#计算随机数x0的平方z
z = x0**2
#将z转换为字符串zs
zs = str(z)
if len(zs) != 8:
#如果小于8位,使用rjust()完成左端补齐工作
zs = zs.rjust(8,'0')
#获取zs的中间4位
z4 = zs[2:6]
else:
#获取zs的中间4位zs=z4
z4 = zs[2:6]
#将z4作为新的种子x0
x0 = int(z4)
#将z4作为随机数加入随机数列表
x.append(int(z4))
print(x)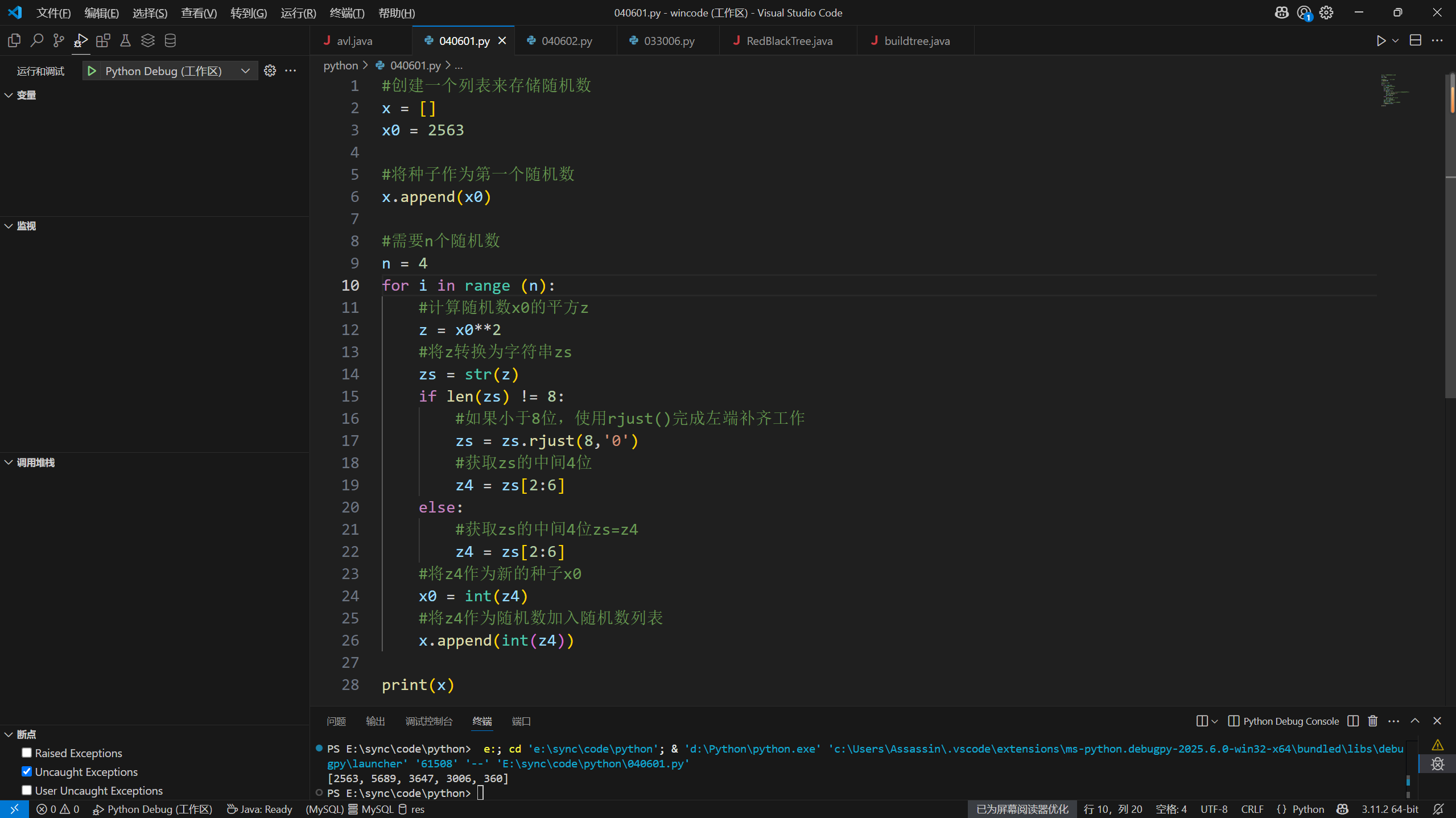
第3题
5个随机数:[0.6717557251908397, 0.16030534351145037, 0.6183206106870229, 0.29770992366412213, 0.12213740458015267]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18x0 = 11
a = 91
c = 4
n = 131
m = 5
x=[]
y=[]
for i in range(m):
s = a * x0 + c
t = s % n
r = t / n
x0 = s
x.append(t)
y.append(r)
print(x, y)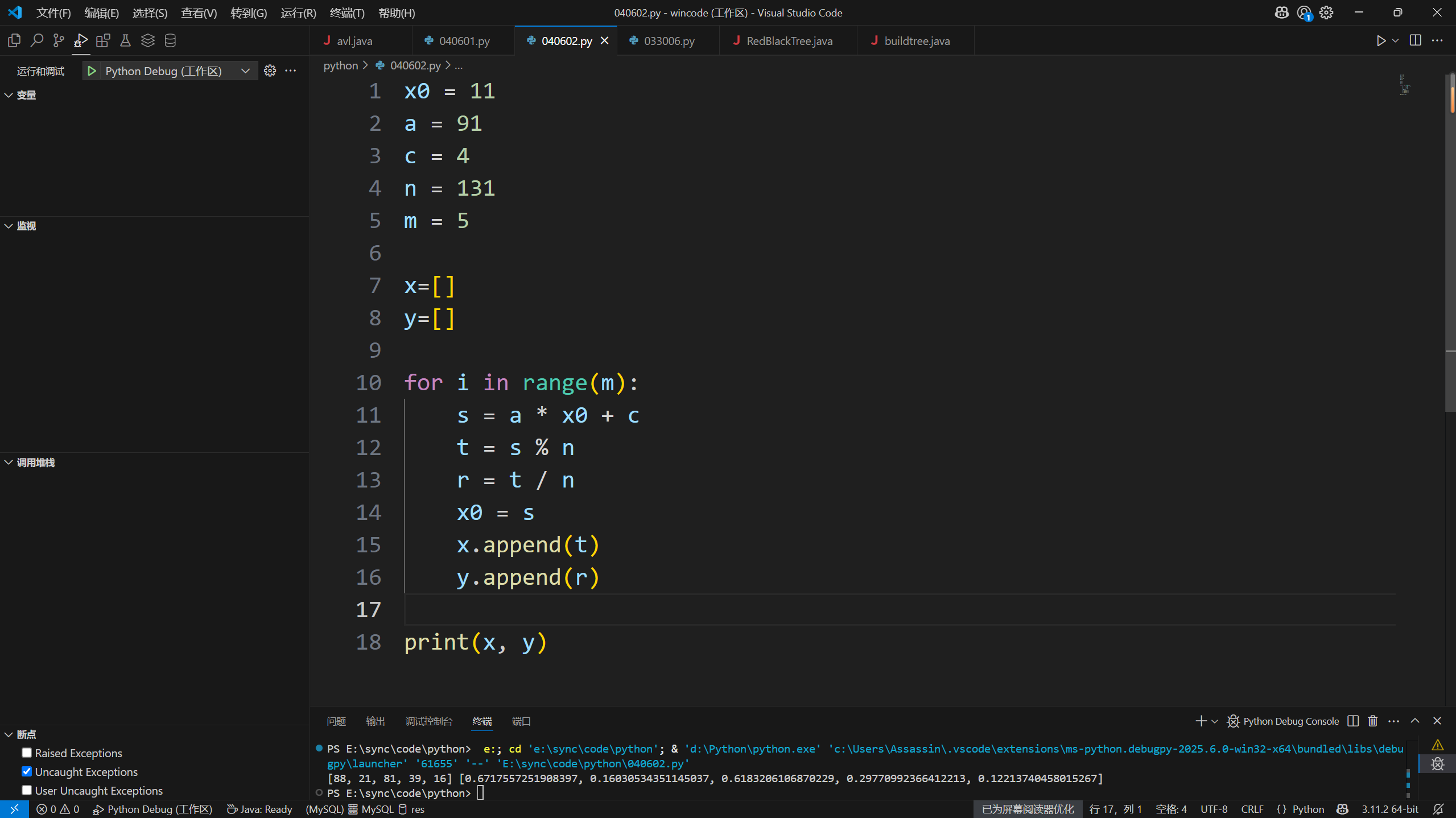
习题2.3
第1题
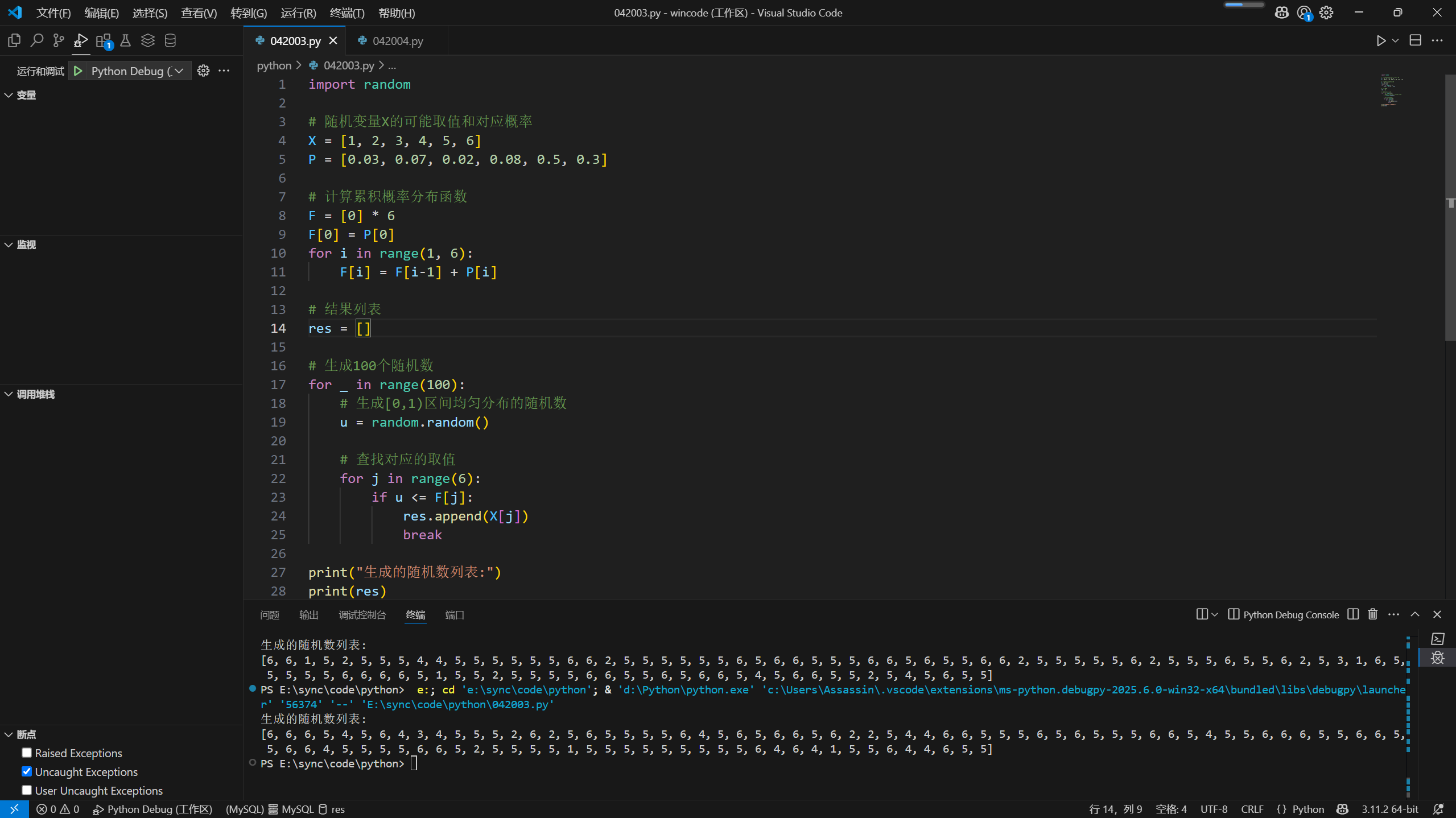
1 | import random |
第2题
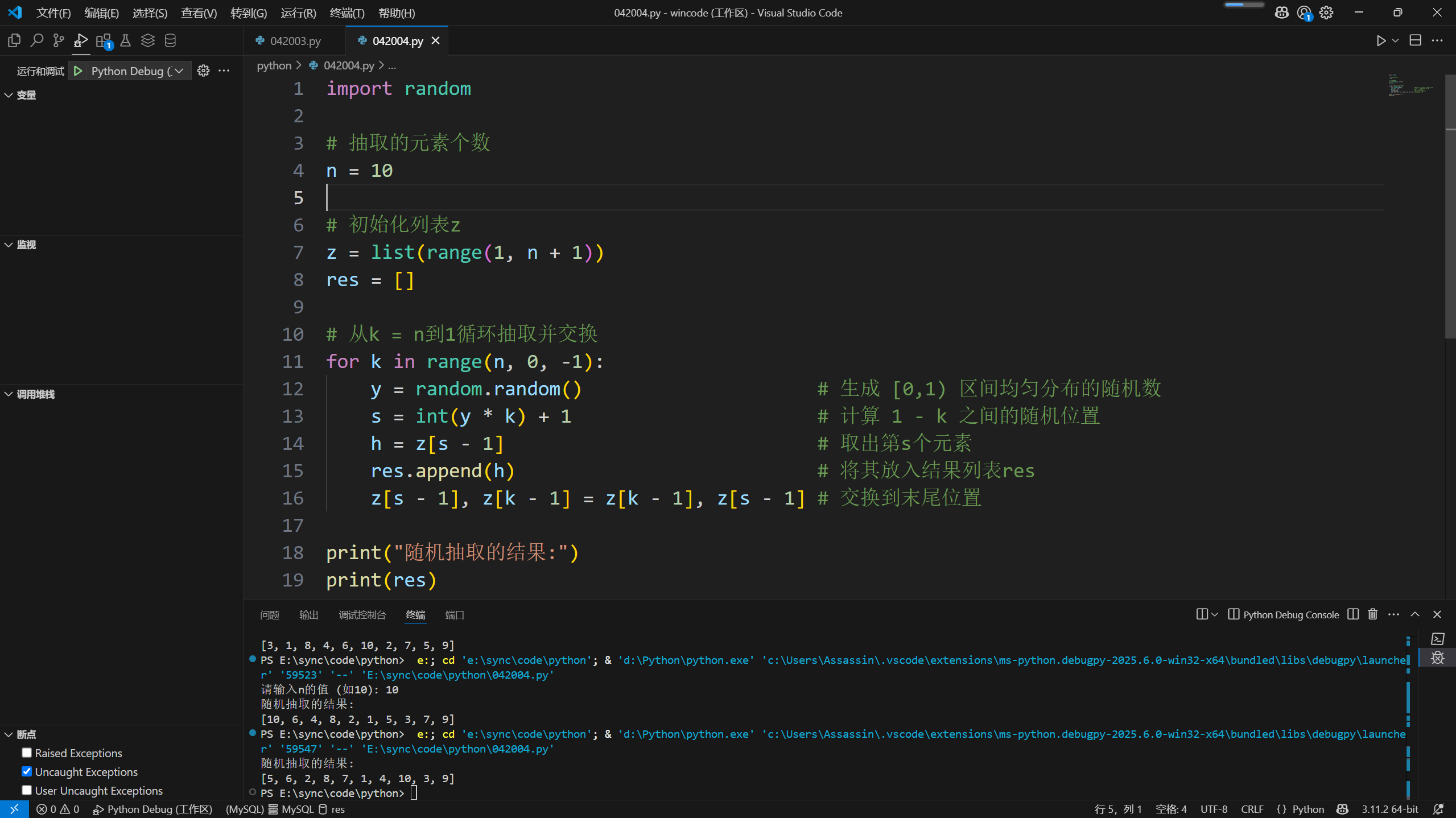
$s=\lfloor y \cdot k\rfloor+1$
1 | import random |
习题2.5
第4题
(1) 逆变换法
分布函数
逆变换
(2)
利用定理:若 $X_1,X_2\sim N(0,1)$ 且独立,则
1 | import numpy as np |
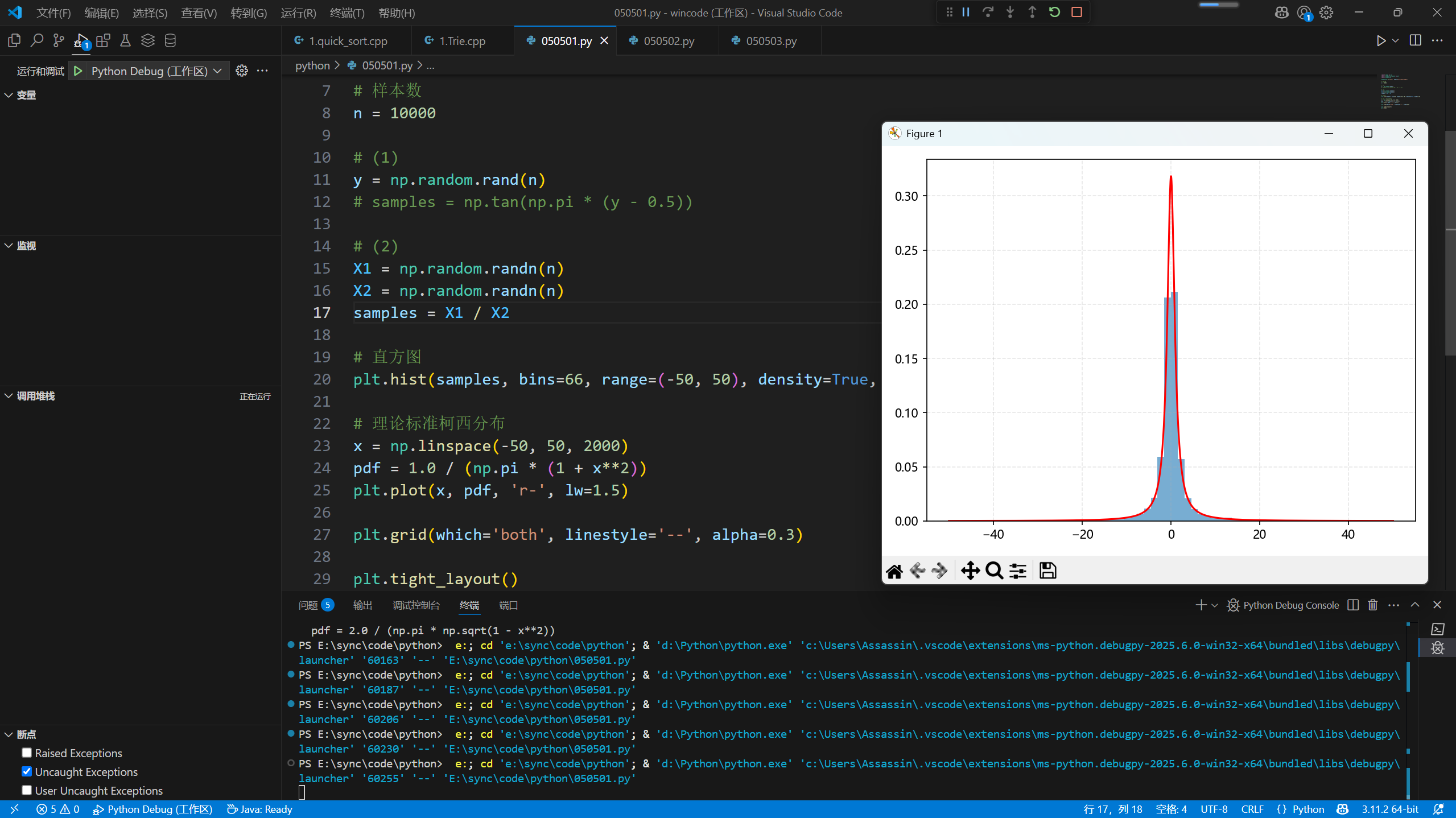
第8题
令 $Y\sim \mathrm{Unif}(0,1)$
1 | import numpy as np |
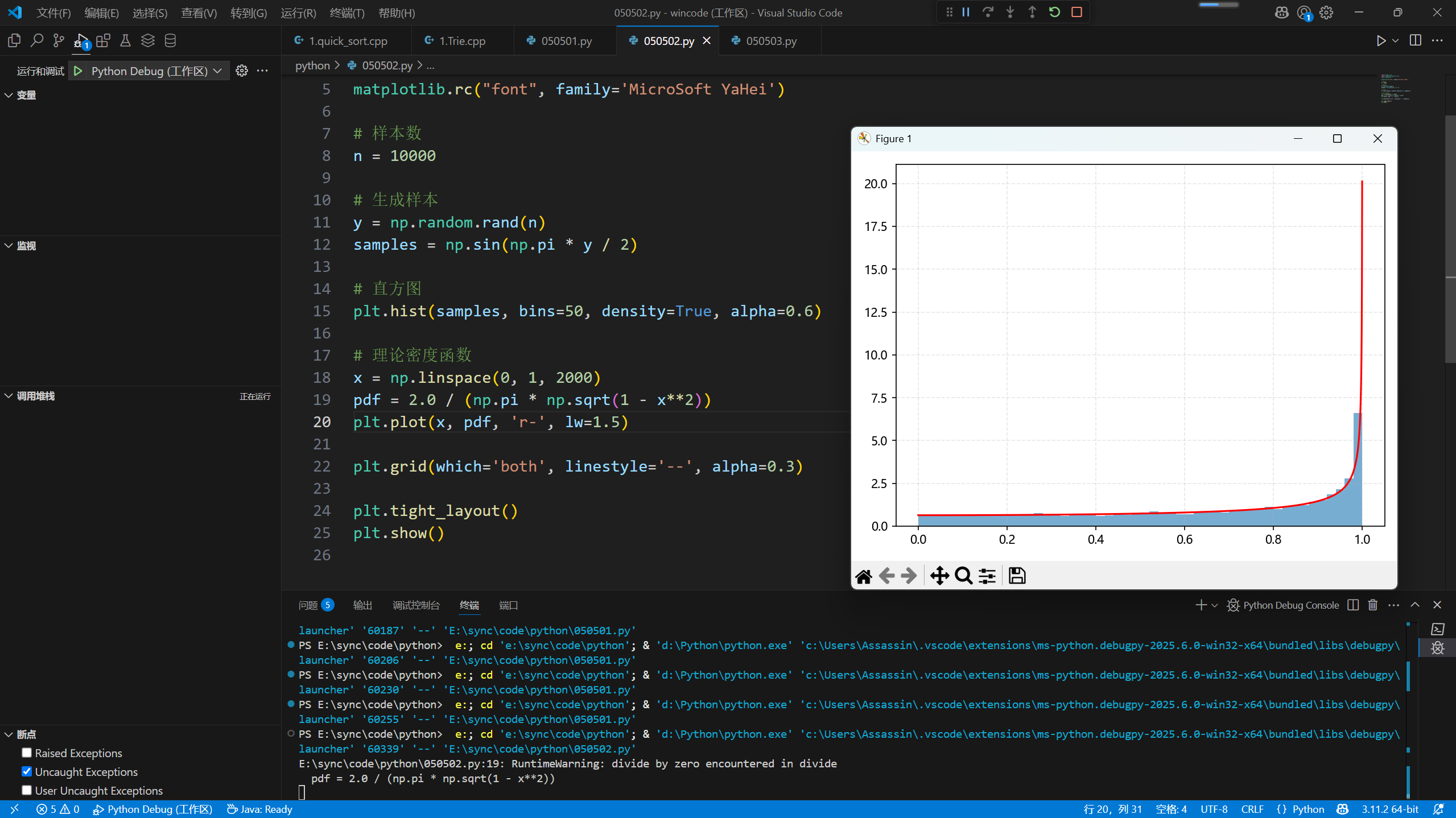
第13题
生成一个从 5 开始、参数为 $\lambda$ 的“平移后”指数分布样本。
标准指数分布:
生成 $u \sim \text{Uniform}(0,1)$。
解 $u = F_{\text{std}}(t) = 1 - e^{-\lambda t}$,得到:
$1 - u$ 与 $u$ 在分布上是等价的(Uniform(0,1)),可以简化为:
平移回 $x = t + 5$,得到:
从 5 开始的指数分布,在任意 $x \geq 5$ 上的概率密度函数是:
1 | import random |
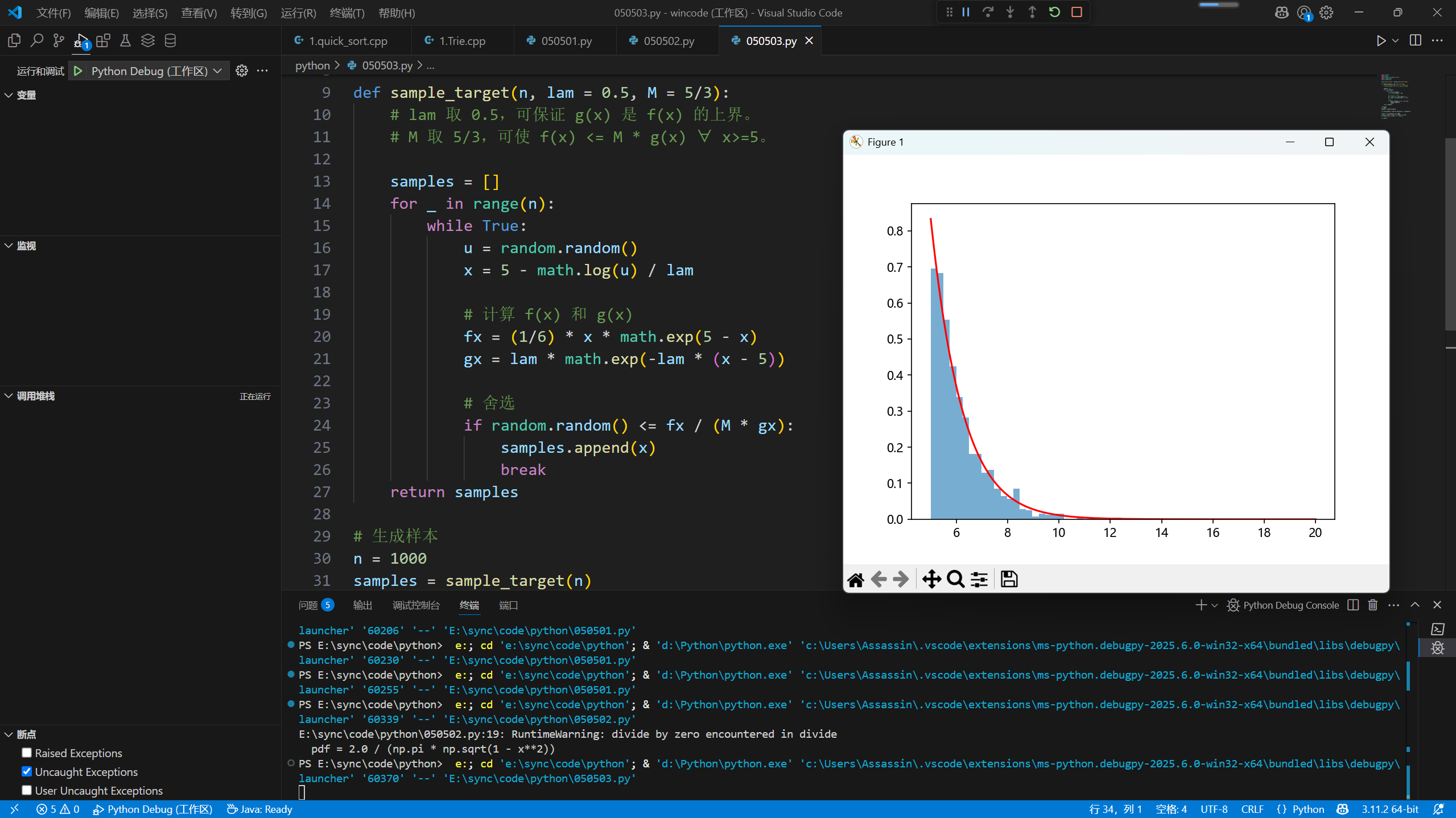
习题3.1
第5题
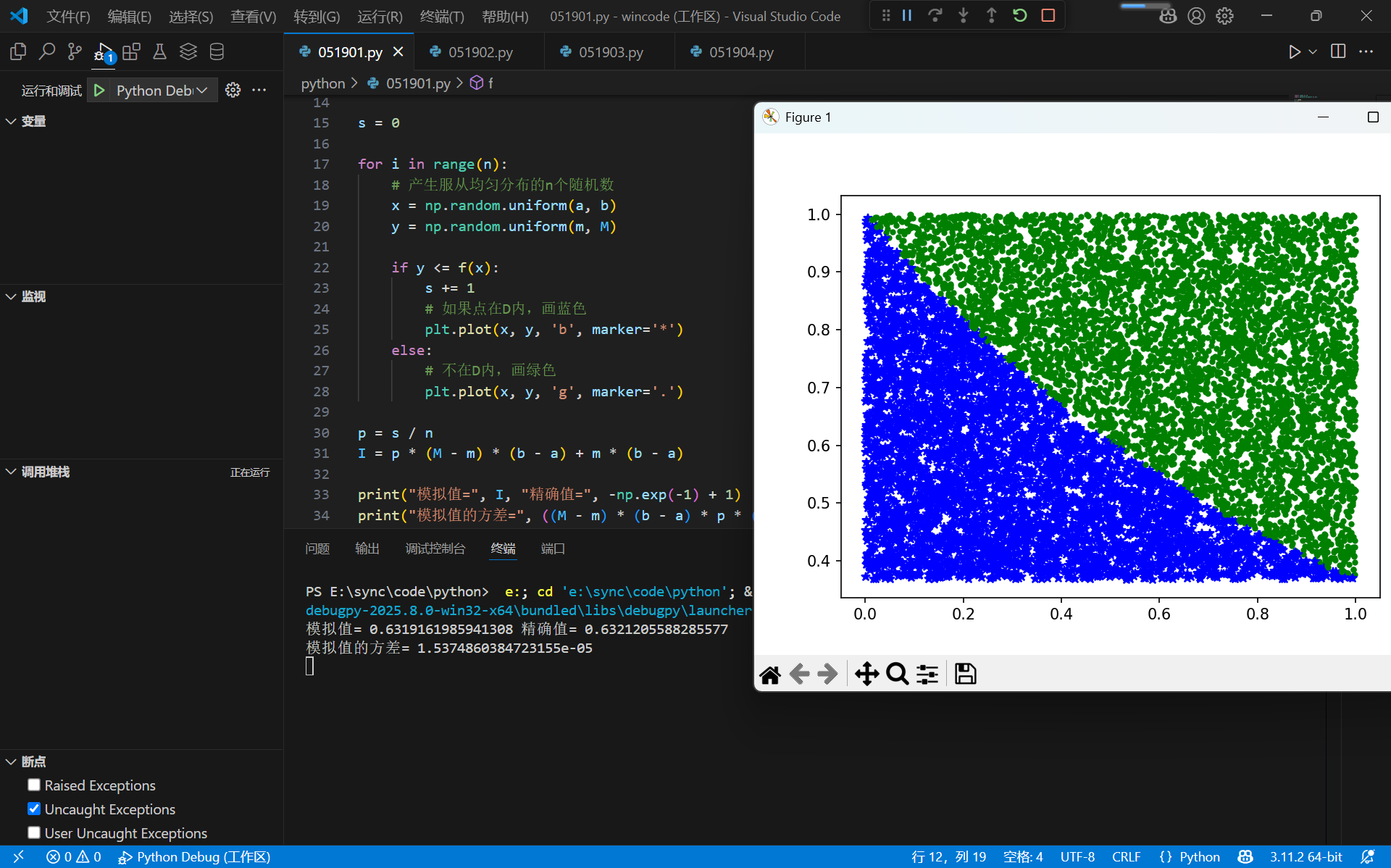
随机投点法
$\hat{I}_1=(b-a)(d-c)p + c(b - a)$
$D\left(\hat{I}_1\right)=\frac{(b-a)(d-c) p(1-p)}{N}$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import numpy as np
import matplotlib.pyplot as plt
n = 10000
a = 0
b = 1
m = np.exp(-1)
M = 1
# 定义函数f(x)
def f(x):
t = np.exp(-x)
return t
s = 0
for i in range(n):
# 产生服从均匀分布的n个随机数
x = np.random.uniform(a, b)
y = np.random.uniform(m, M)
if y <= f(x):
s += 1
# 如果点在D内,画蓝色
plt.plot(x, y, 'b', marker='*')
else:
# 不在D内,画绿色
plt.plot(x, y, 'g', marker='.')
p = s / n
I = p * (M - m) * (b - a) + m * (b - a)
print("模拟值=", I, "精确值=", -np.exp(-1) + 1)
print("模拟值的方差=", ((M - m) * (b - a) * p * (1 - p)) / n)
plt.show()
平均值法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import numpy as np
a = 0
b = 1
# 定义函数 f(x)
def f(x):
return np.exp(-x)
# 定义 f(x) 的原函数 F(x)
def F(x):
return -np.exp(-x)
# 试验次数
n = 10000
# 取服从 [a,b] 均匀分布的 n 个随机数
x = np.random.uniform(low=a, high=b, size=n)
# 计算函数值
y = f(x)
# 矩形法计算定积分近似值:面积 = 宽度 * 平均高度
M = (b - a) * np.sum(y) / n
# 精确值
I = F(b) - F(a)
var_M = (b - a) * np.var(y, ddof=1) / n
print("模拟值 =", M, "精确值 =", I)
print("模拟值的方差 =", var_M)重要抽样法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import numpy as np
n = 10000
h = []
a = 0
b = 1
# 定义 f(x) 的原函数 F(x)
def F(x):
return -np.exp(-x)
for i in range(n):
# 取服从[0,1]均匀分布的随机数
u = np.random.random()
# 反函数法从 g(x) 中抽样
x = -np.log(1 - (1 - np.exp(-1)) * u)
# 目标函数 f(x)
f = np.exp(-x)
# 拟合函数 g(x)
g = np.exp(-x) / (1 - np.exp(-1))
# 计算 f/g 比值
y = f / g
h.append(y)
# 精确值
I = F(b) - F(a)
M = np.sum(h) / n
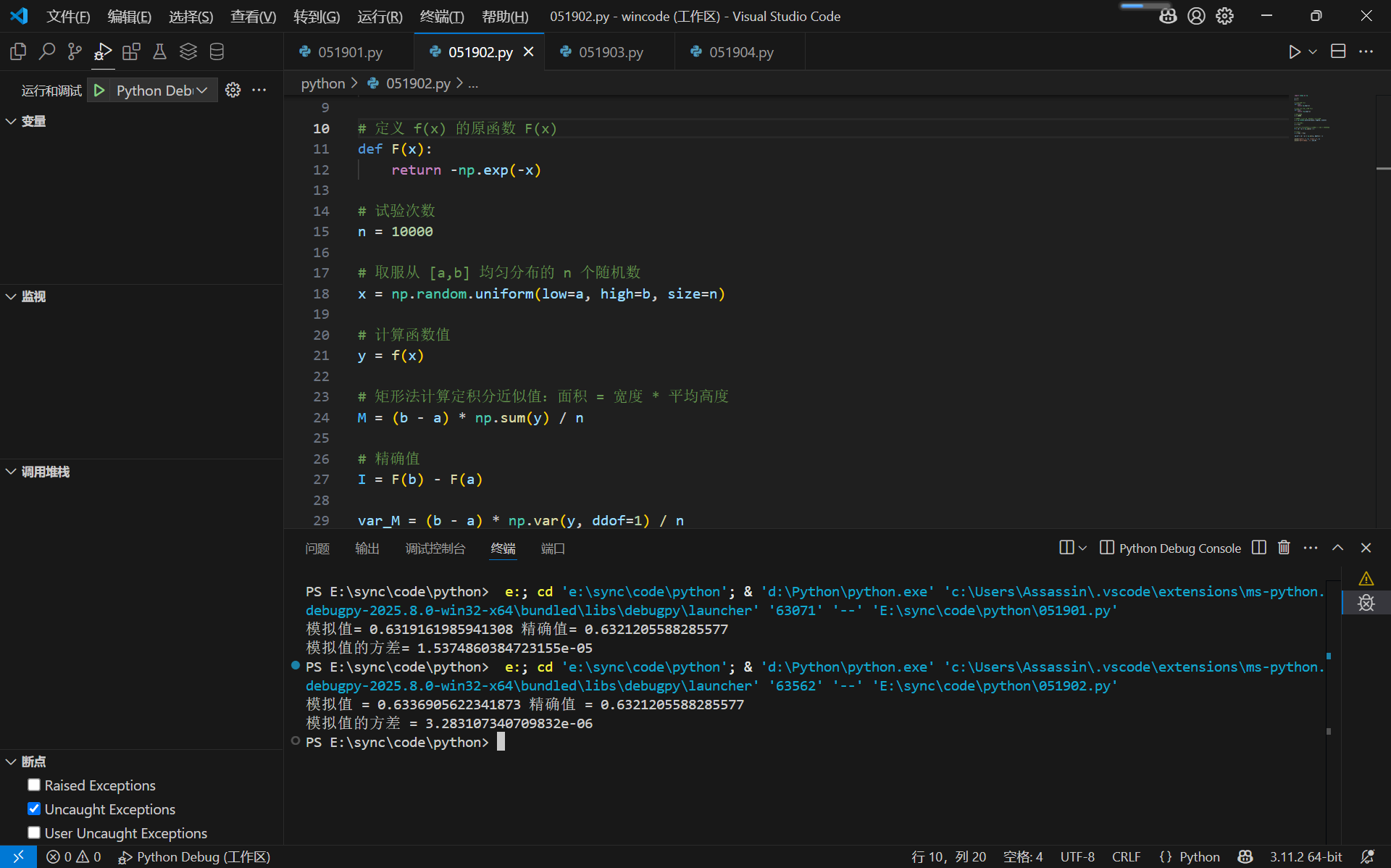
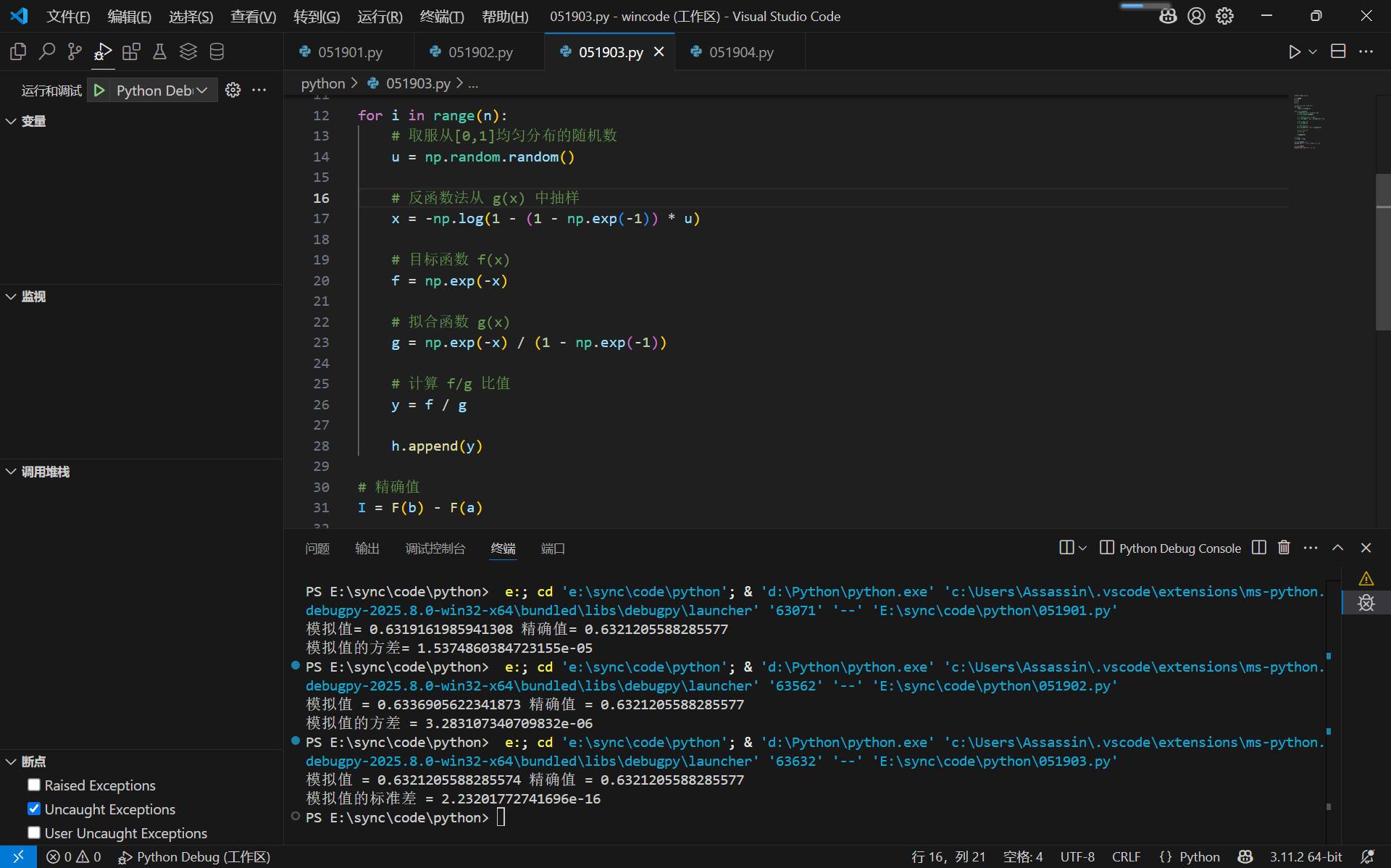
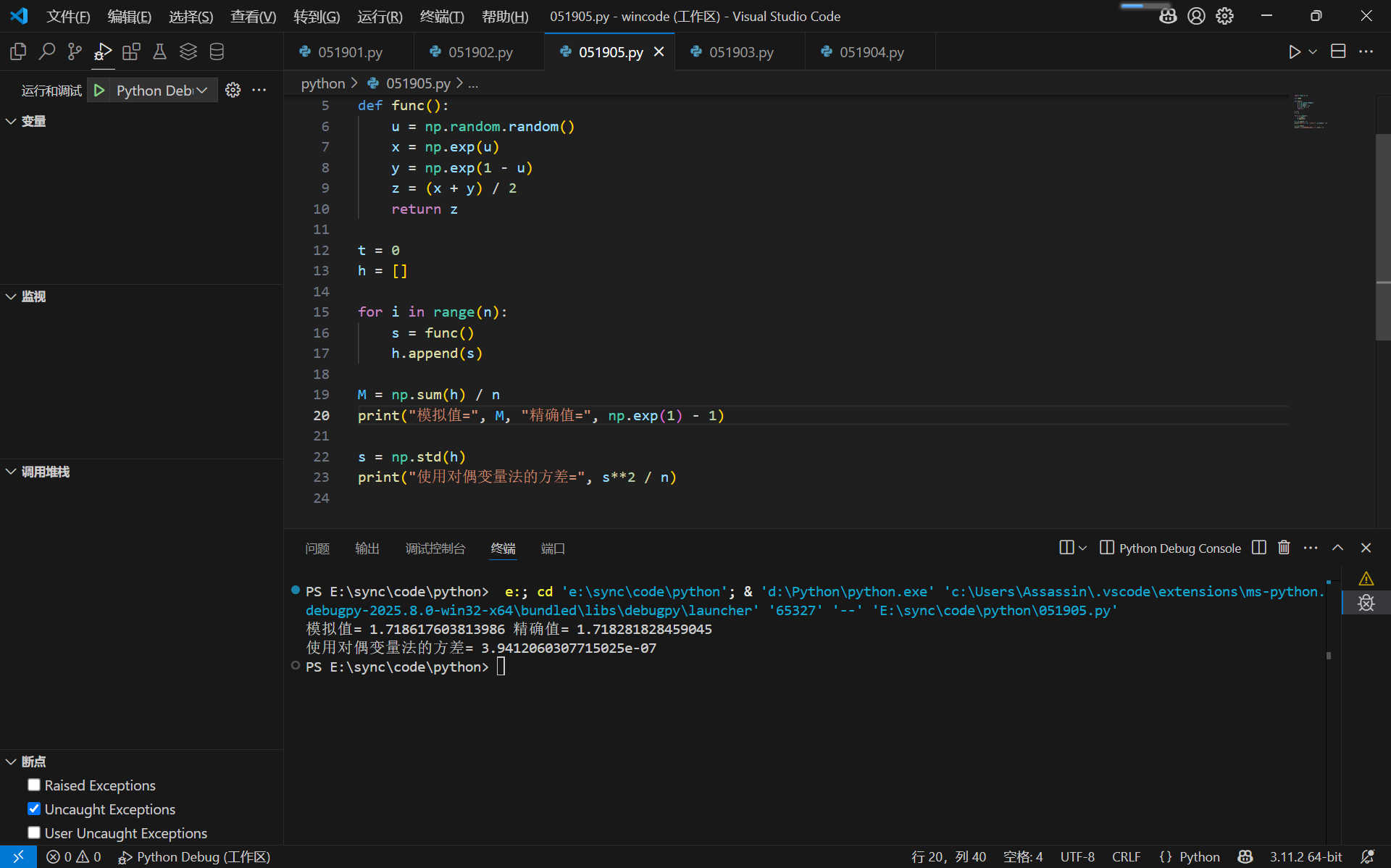
print("模拟值 =", M, "精确值 =", I)
s = np.std(h)
print("模拟值的标准差 =", s)
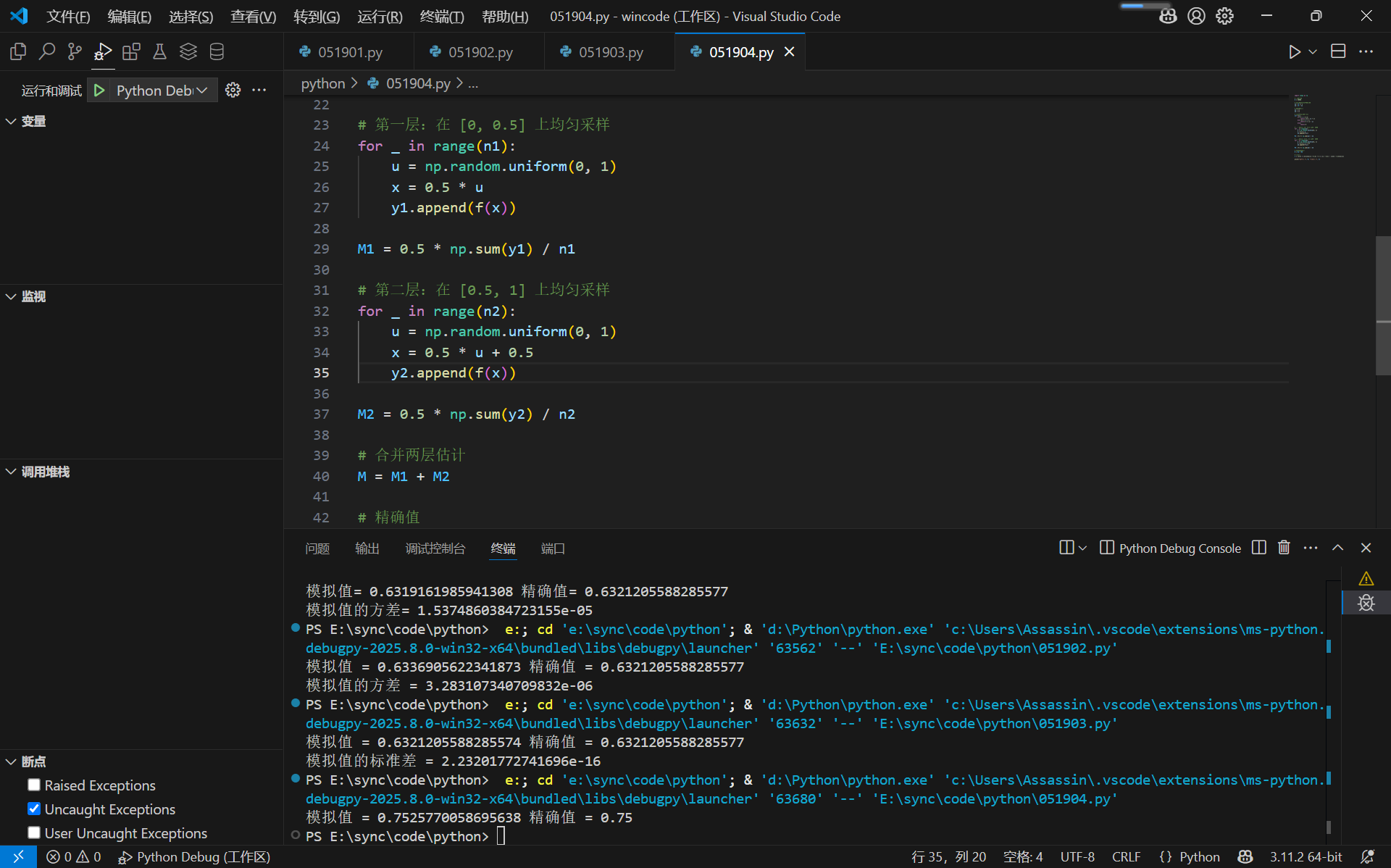
第6题
1 | import numpy as np |
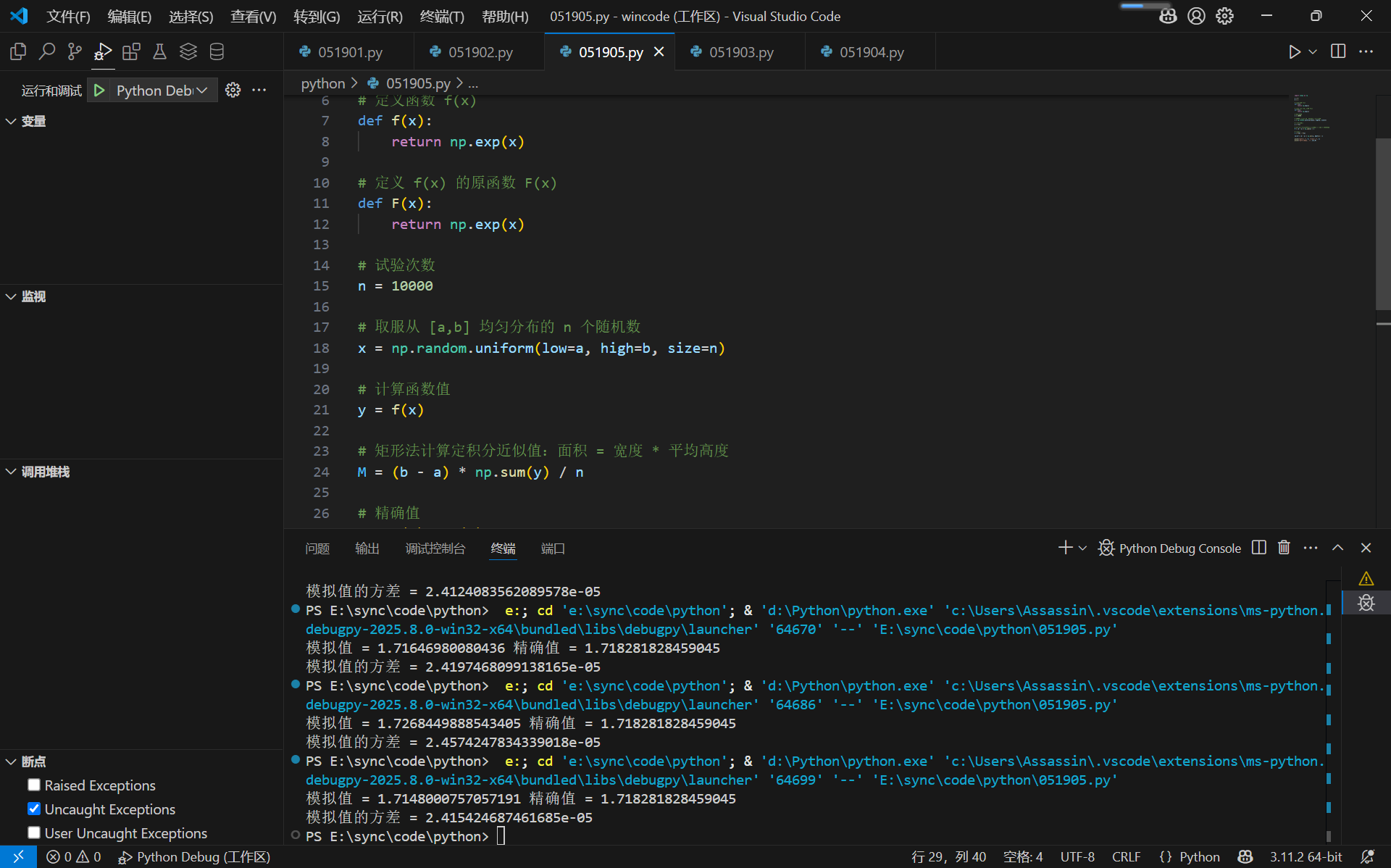
习题3.2
第2题
1 | import numpy as np |
1 | import numpy as np |
习题3.3
第1题
一颗骰子掷 4 次至少得到一个 “6”
两颗骰子掷 24 次至少得到一个 “双六”(6,6)
一颗骰子掷 4 次至少出现一次 “6” 的概率更大。
第4题
累计分布函数不超过 $m$ 的概率:
Python计算最小整数 $m$ :
- $P(X \le 15) \approx 0.99759 < 0.999$
- $P(X \le 16) \approx 0.99904 \ge 0.999$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import math
def poisson_cdf(k, lam):
return sum(math.exp(-lam) * lam**i / math.factorial(i) for i in range(k+1))
lam = 7 # 泊松分布参数 λ
target = 0.999 # 累计概率目标
m = 0
# 找到最小的 m,使得 P(X ≤ m) ≥ 0.999
while True:
if poisson_cdf(m, lam) >= target:
break
m += 1
print(f"每月至少要备货 m = {m} 盒冰粽,才能有 0.999 的概率满足需求。")
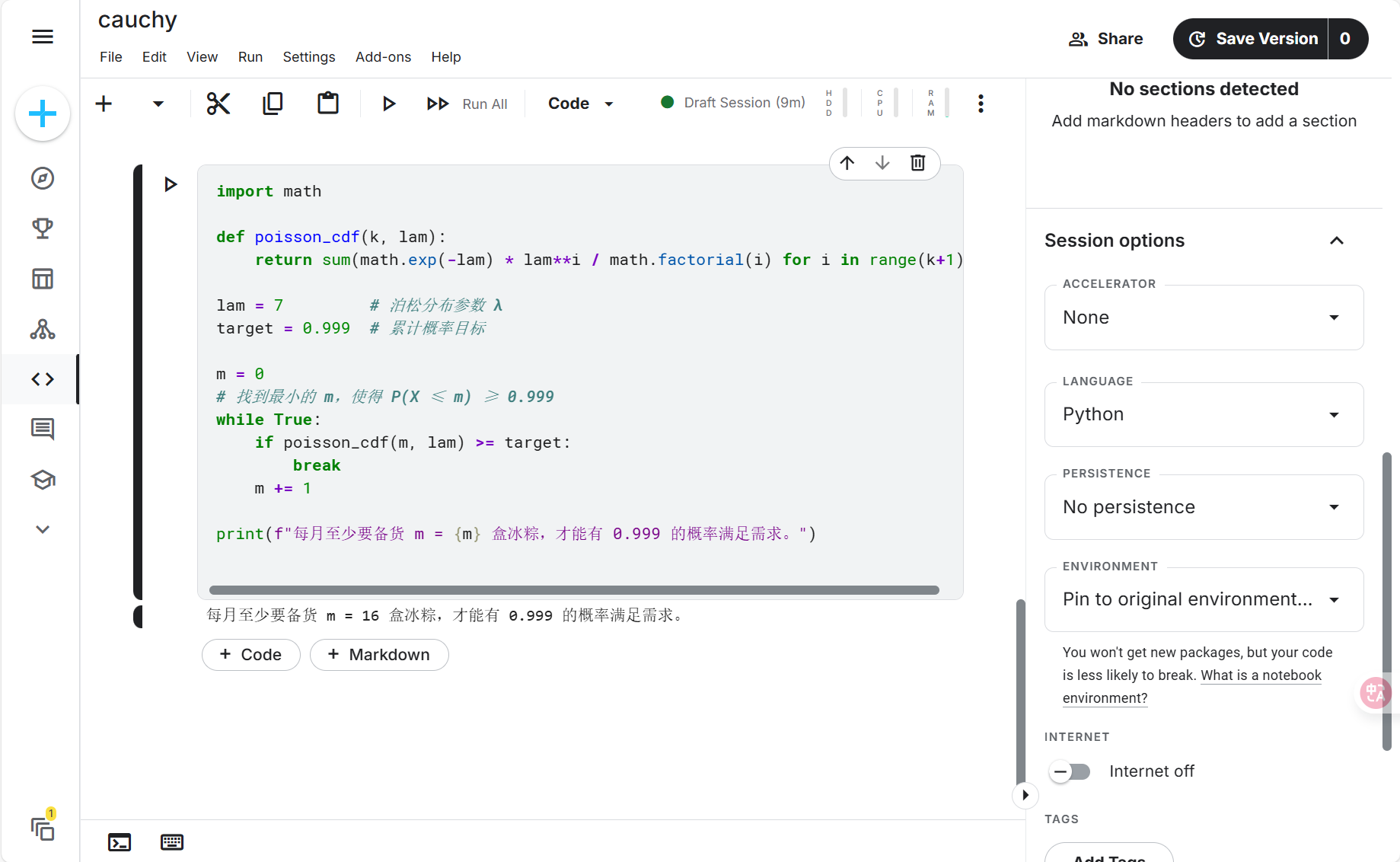
每月需要至少销售 16 盒冰粽,才能保证有 $99.9\%$ 的概率完成业绩要求。
习题3.4
第5题
1 | import numpy as np |
第13题
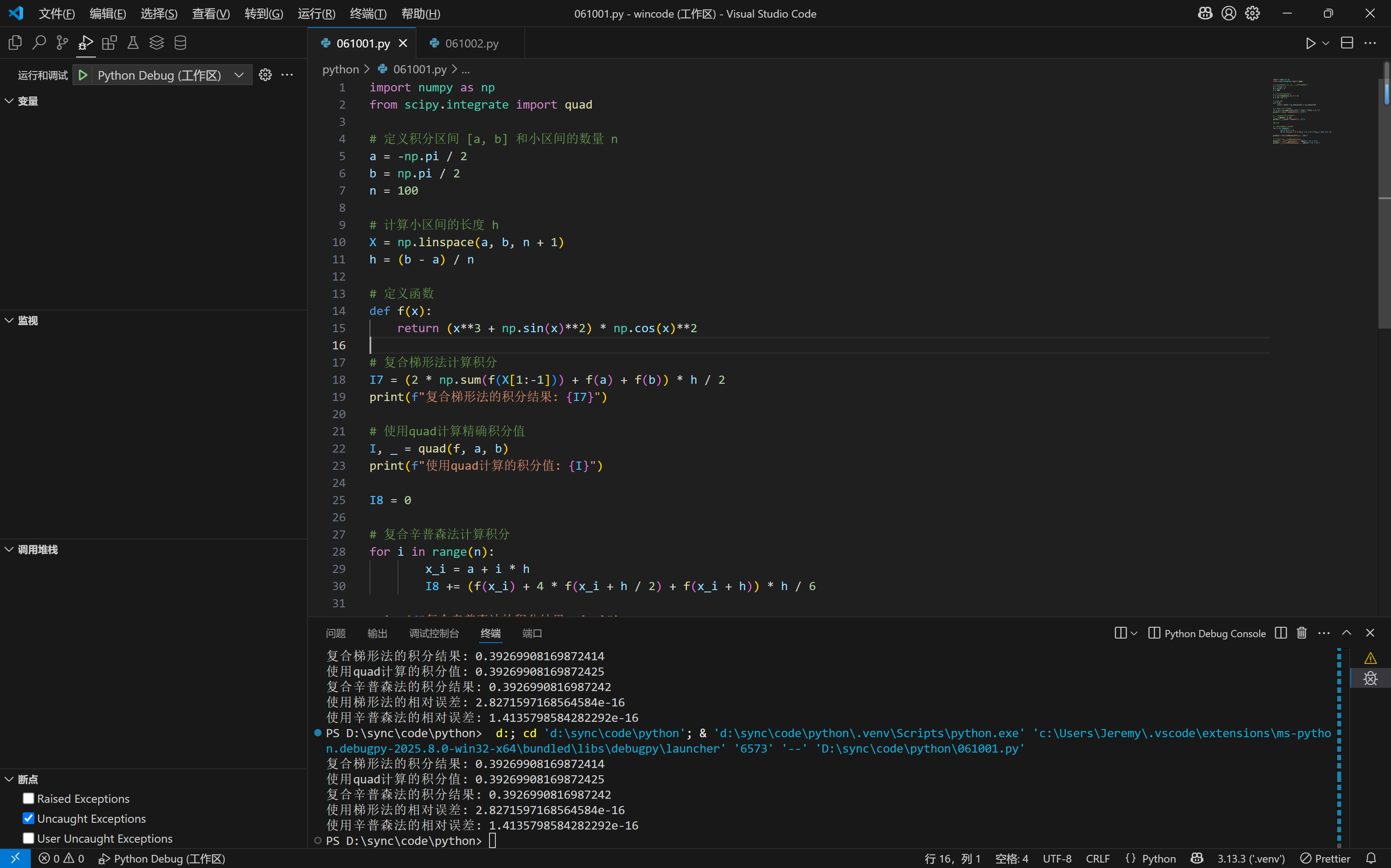
复合梯形公式为
1 | import numpy as np |
复合辛普森公式为
1 | import numpy as np |